Century Games - User Statistic Assistant
Beijing July 2021 - December 2021
As a user statistic assistant, I continuously monitored user experiences from closed to open beta, analyzed player retention, and devised data-driven strategies for a 3% increase in the 3-day retention rate. I also designed and analyzed surveys during 3-day, 7-day, and 14-day testing phases, and conducted in-depth interviews to identify reasons for player churn during the 7-14 day period, producing actionable reports.
Baidu - Business Analytics Assistant
Beijing September 2020 - December 2020
As a bussiness analytics assistant, I conducted in-depth industry research on online education and adult education, exploring dimensions such as market trends, sub-sectors, key players, and competitors. Through thorough desktop research, I analyzed the existing business models across various segments of the industry value chain. The findings provided a comprehensive understanding of the industry's current landscape. Subsequently, I offered strategic support for Baidu Library's market entry, drawing on insights gained from the analysis.
Giance Technologies - Data Analytics Assistant
Beijing May 2019 - August 2019
As a data analytics assistant, I cleaned and annotated over 10,000 records in the database, and assisted to train the company's classificaiton model with the cleaned data, Additionally, I developed a Python web scraper to collect financial news from more than 10 reputable companies as new materials for the company's NLP model.
ENSAE - Research Assistant
Paris February 2023 - September 2023
Working with the professor on the project of Inference on SNDS databse with quantitative measurement, I simulated bipartite data between patients and doctors corresponding to the calibrated model, and estimated the potential costs of each visits with a second-ordred model. Besides, I estimated two-way fixed effects and coefficients with logistic regression model based on the simulated bata, and in the end evaluated the results with different methods including euclidean norms and cross validation, and validated the results via analysis on bigger scale of data with Spark.
Research on Dissemination Strategy of Changchun on Tiktok
Paris October 2022 - January 2023
As the first author of this research, I developed a web scraper using HTMLSession to collect 500+ videos and relevant data on Tiktok platform, and conducted basic statistical analysis. I then constructed first-order and second-order regression model to delve into the relative impact of various factors on city brand's dissemination heat.
A Case Study of Customer Segmentation
Paris October 2022 - December 2022
For this case study, I preprocessed the data via 3 stages, data cleaning, exploratory data analysis, and feature engineering, after which I built different classification models including KNN, Adaboost, and randomforest. With the results, I evaluated those models with metrics including precision rate, recall rate, and f1-socre, and drew the conclusion that the randomforest classifier performed comparatively better on this dataset.
Toxic Comment Classification
Paris November 2023 - January 2024
In this competition, we first conducted exploratory data analysis and observed the critical features of the dataset. Based on the observation, we preprocessed the data, including cleaning unicodes, emojis, and tones.
Before training models, we tested and built our embedding matrix with pre-trained word vectors. After experiments, we chose glove.840B.300d since it has better performance.
During model traning, we applied cross-validation to obtain more stable results and avoid overfitting. Moreover, in consideration of diversity among the models for stacking,
we applied different numbers of folds for cross validation and also different numbers of epoches on different models.
In terms of models, we trained Bi-LSTM, Bi-GRU with attention, CNN, and BERT.
In the end, we stacked our models altogether to improve our score in the competition.
For the second-order model, we tried Linear Regression, Logistic Regression, and SVM. Finally, we imported hyper features obtained from the base models to the second-order model
and predict the ultimate results of our comments.
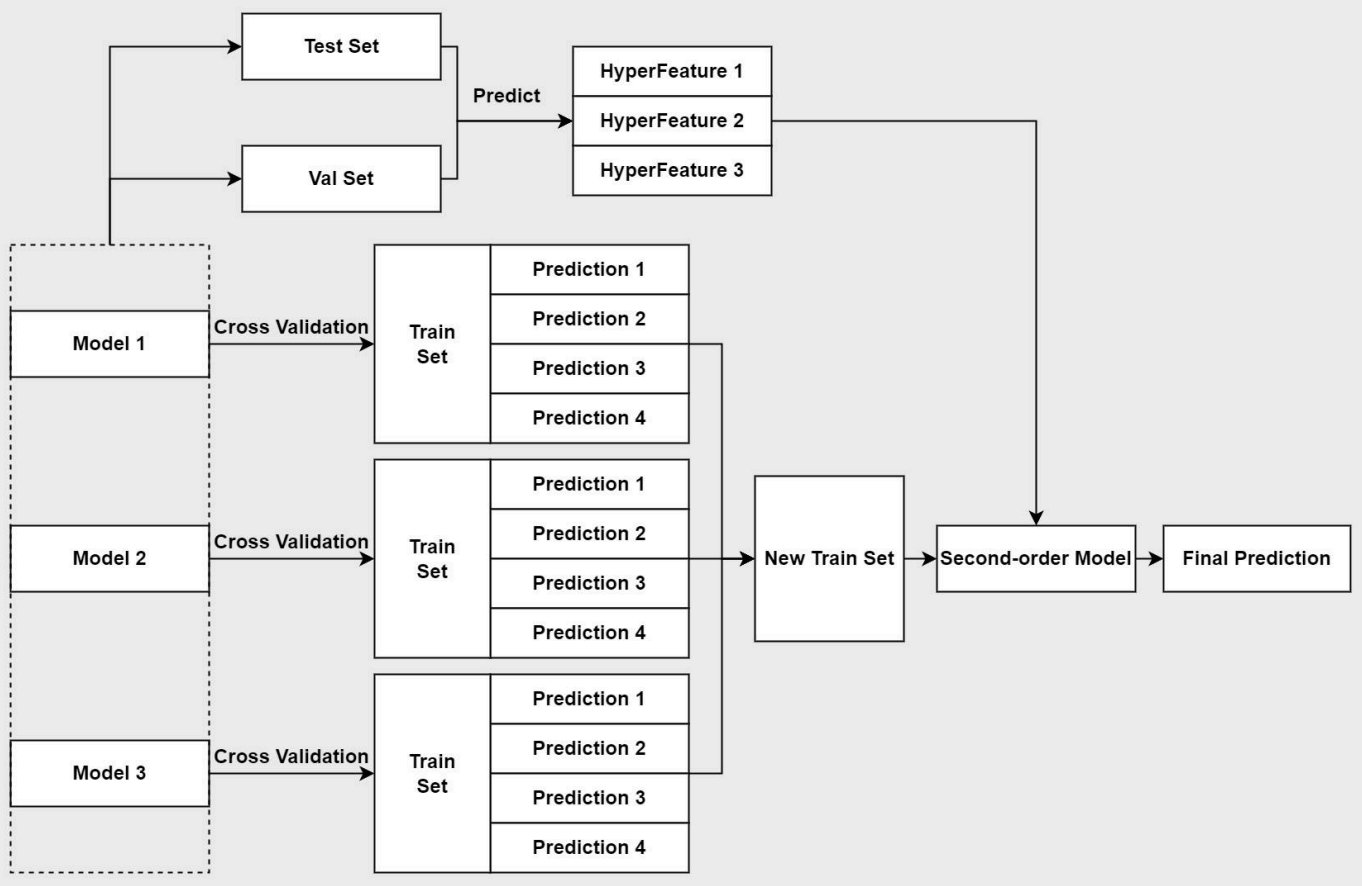
Process of Stacking
Our final stacked model ranked top 3 in this in-class kaggle competition.
Full report and codes could be found on github: https://github.com/xiangyang0608/toxiccommentclassification.git